Why Chatbots Fail at Character Counting: A Detailed Test

Image Credit: Sam Balye | Splash
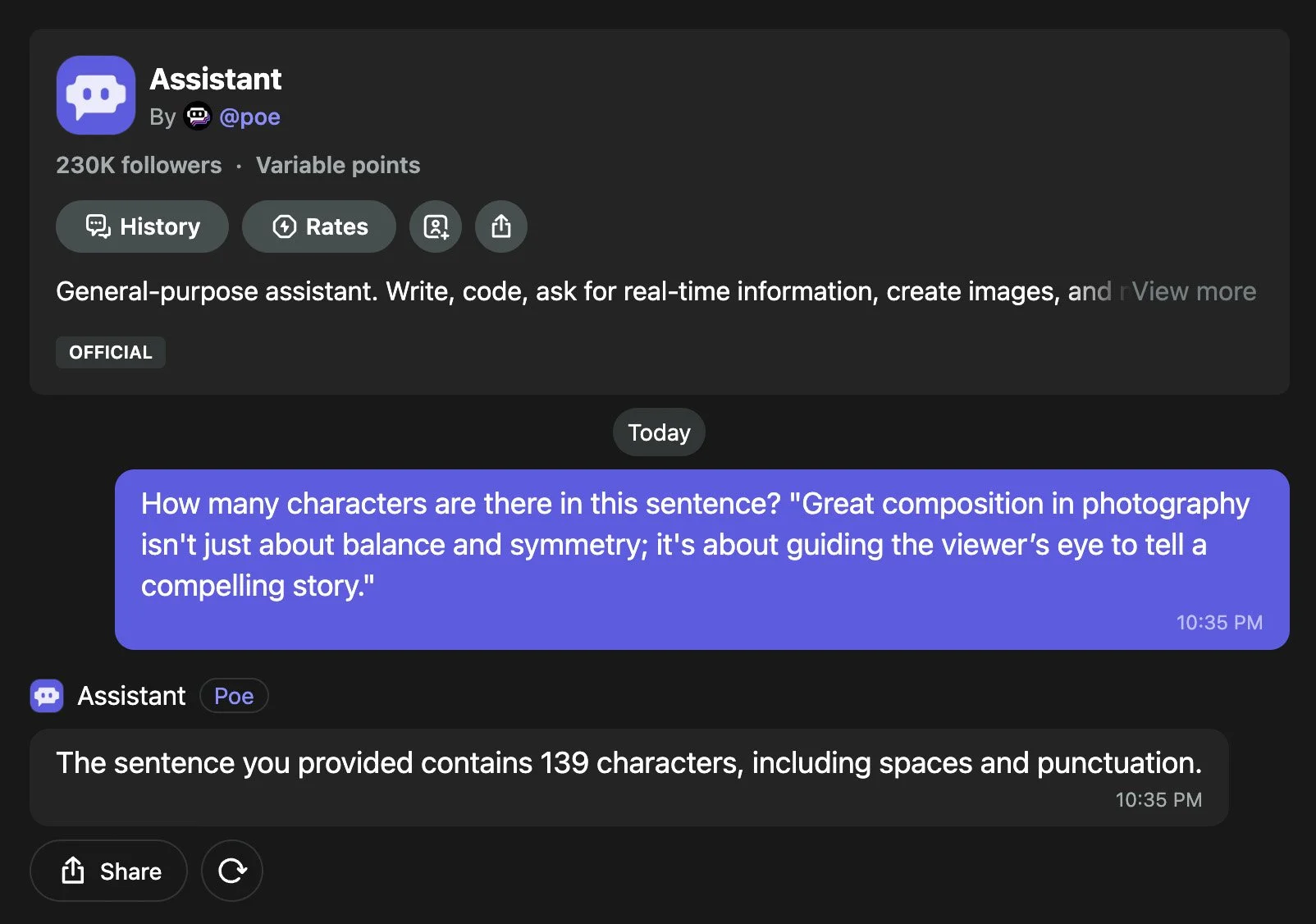
Screenshot from POE.
Chatbots have become indispensable in the digital age, yet their ability to perform a seemingly simple task—counting characters in a sentence—reveals striking differences in accuracy and approach. Our recent test, using the sentence "Great composition in photography isn’t just about balance and symmetry; it’s about guiding the viewer’s eye to tell a compelling story" (135 characters, including spaces and punctuation), exposed these variations. This report analyzes the methods behind the results, exploring whether they reflect AI agent behaviour, reinforcement learning, or human-like processes, and what this means for their efficiency and reliability.
[Read More: DeepSeek AI Among the Least Reliable Chatbots in Fact-Checking, Audit Reveals]
The Test Results: A Spectrum of Performance
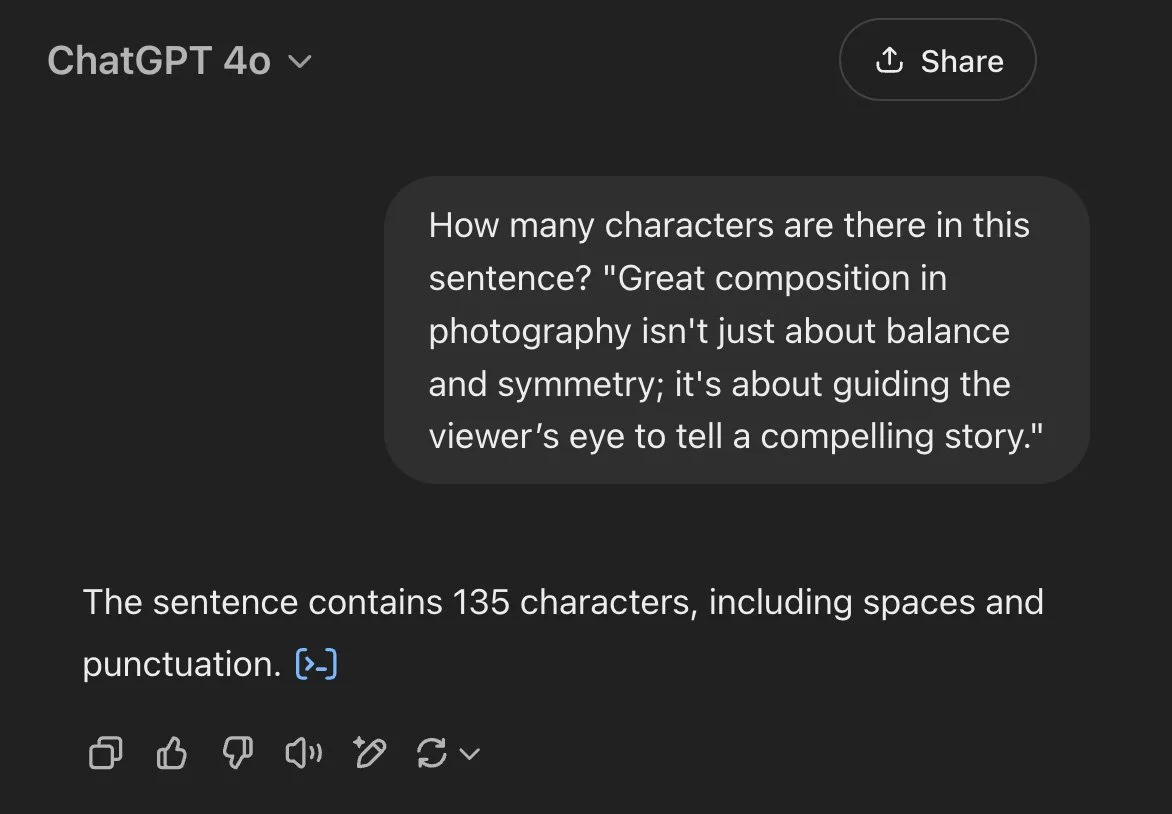
Screenshot from OpenAI ChatGPT 4o.
Our experiment tested leading chatbots, yielding a range of outcomes. ChatGPT 4o and Perplexity (in ‘Pro’ mode) delivered the correct 135 characters swiftly, leveraging a programming-like approach. Grok 3, in standard mode, reported 114 but corrected to 135 in ‘Think’ mode after 73 seconds. Perplexity’s standard mode gave 132, while POE returned 139, Meta AI 146, and Gemini 2.0 Flash 153 (dropping to 140 in ‘Flash Thinking’ mode). Claude 3.7 Sonnet hit 135 accurately in standard mode, and DeepSeek’s ‘DeepThink R1’ mode reached 135 after 153 seconds, compared to 150 in standard mode. These disparities prompted a closer look at each model’s method.
[Read More: ChatGPT Pro vs. Plus: Is OpenAI's $200 Plan Worth the Upgrade?]
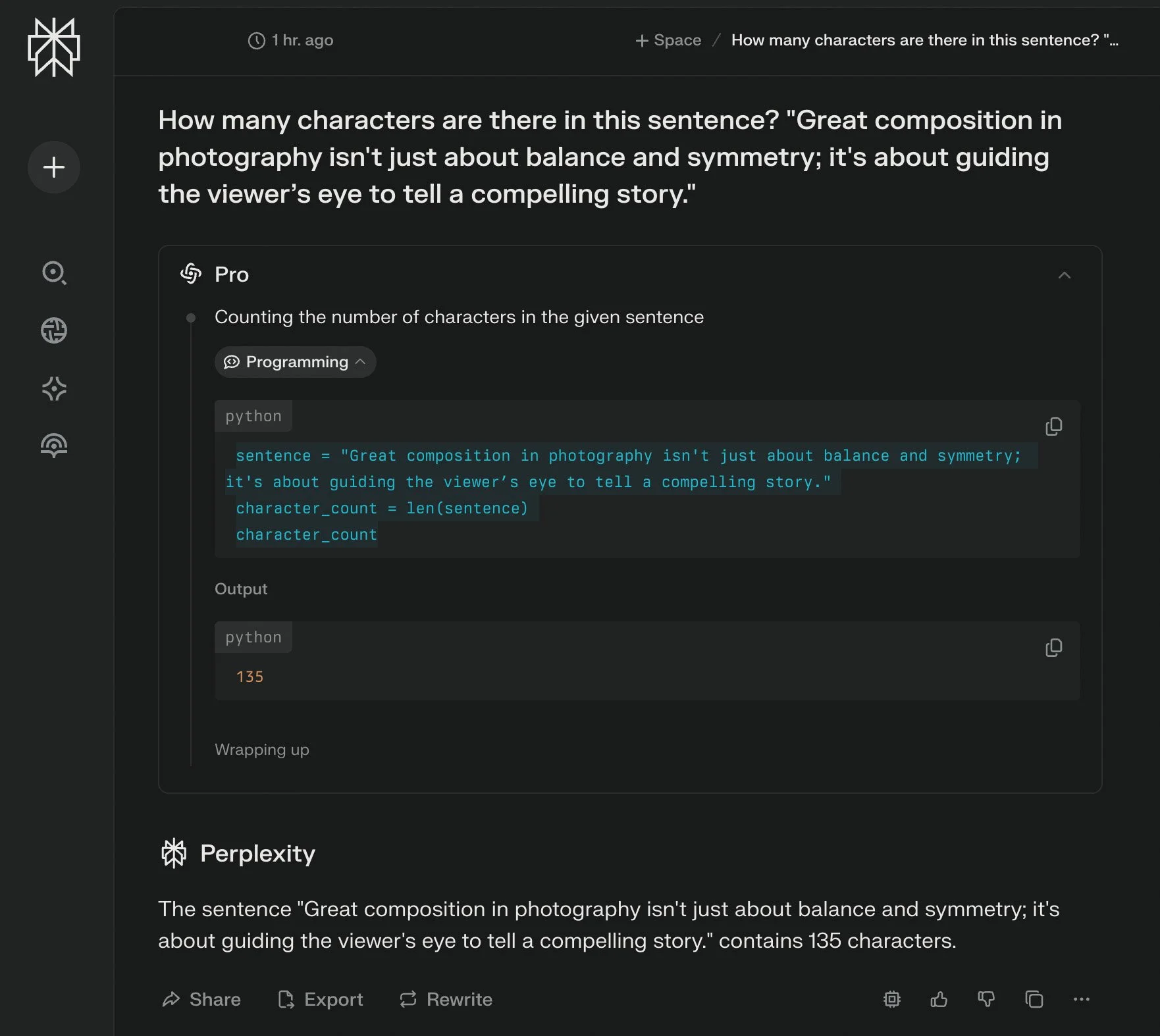
Screenshot from Perplexity (in ‘Pro’ mode).
Programming Precision: ChatGPT 4o and Perplexity as AI Agents?
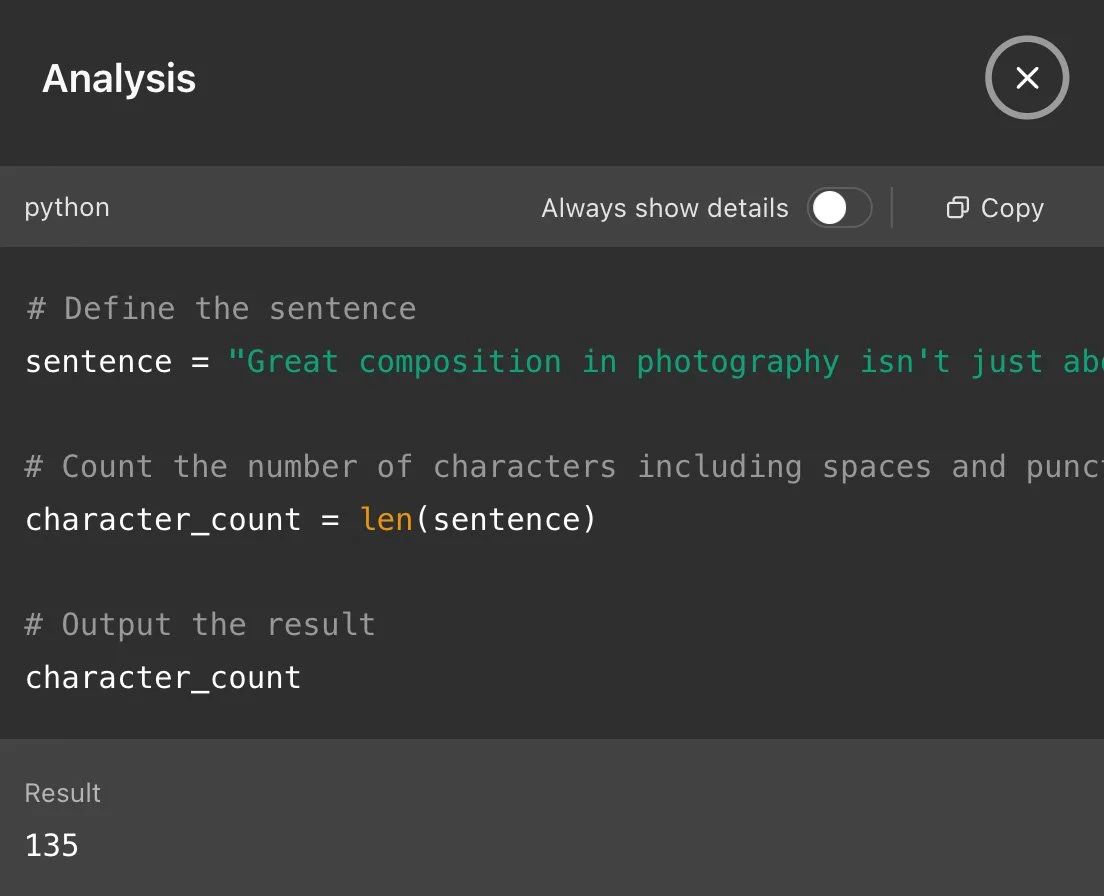
Screenshot from OpenAI ChatGPT 4o.
ChatGPT 4o and Perplexity (Pro mode) stood out for their efficiency, both returning 135 characters almost instantly. Their responses suggest they directly invoked a Python-like formula—akin to sentence = "..." followed by len(sentence)—mimicking a programming function that counts every character, space, and punctuation mark. This approach is the fastest and most reliable, raising the question: are they acting as AI agents? In AI terminology, an agent autonomously selects tools or methods to solve problems. By opting for a programmatic solution rather than natural language estimation, these models demonstrate agent-like behaviour, prioritizing accuracy and speed over conversational flair. This efficiency contrasts sharply with models that stumble without such tools.
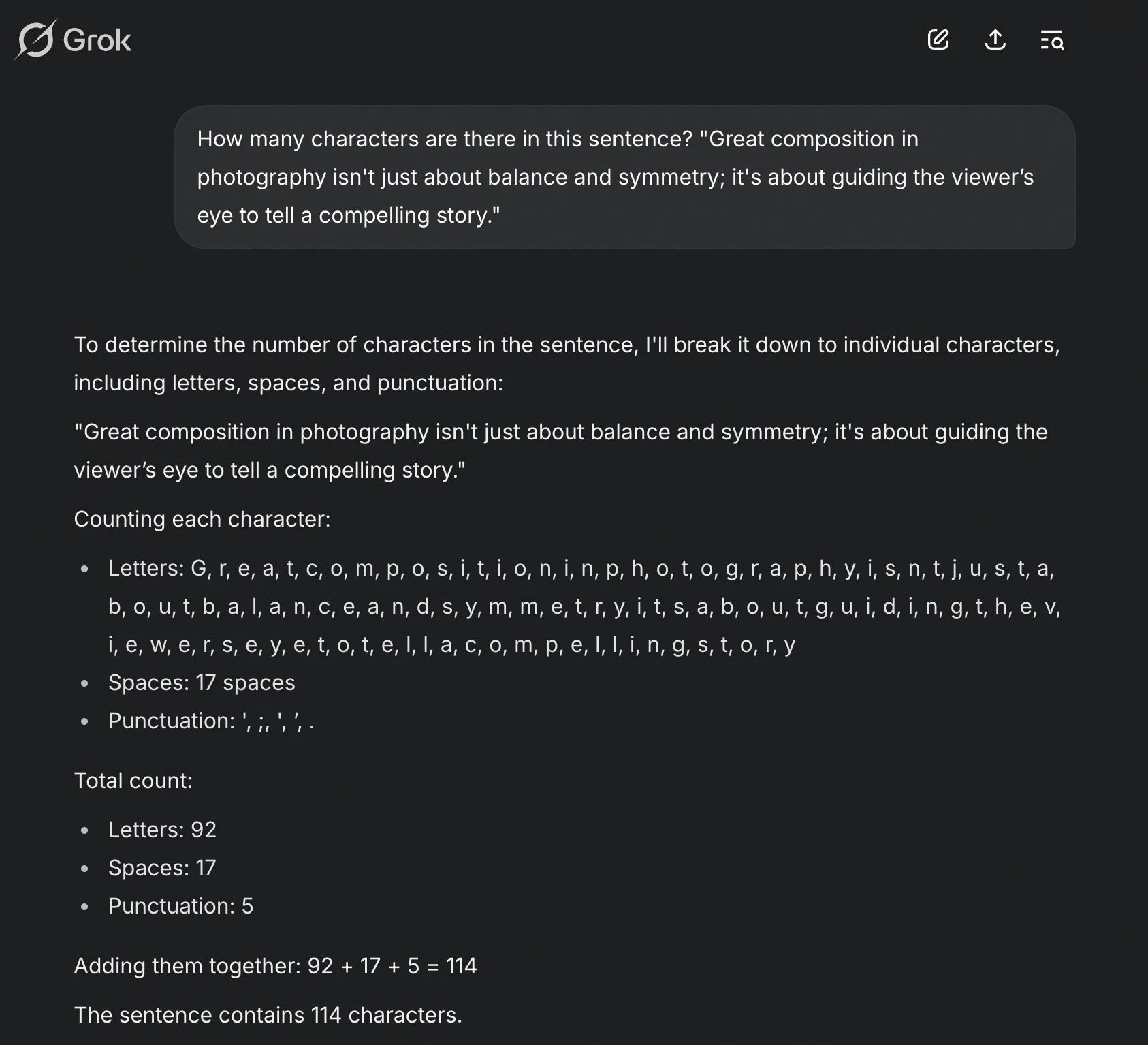
Screenshot from Grok 3 (in standard mode).
Grok 3’s ‘Think’ Mode: Reinforced Learning or Structured Reasoning?
Grok 3’s ‘Think’ mode corrected its initial 114-character error to 135, taking 73 seconds and detailing its process: breaking the sentence into tokens, summing characters in word tokens, counting spaces, calculating the total, and verifying with an alternative method (counting letters, punctuation, and spaces separately). This step-by-step breakdown resembles reinforced learning (RL), where an AI refines its output through iterative feedback. However, it may also reflect structured reasoning—pre-programmed steps to ensure accuracy—rather than dynamic learning during the task. The 73-second delay suggests computational overhead, but the verification step mirrors human double-checking, balancing accuracy with a moderate time cost.
[Read More: Examining Grok 3’s “DeepSearch” and “Think” Features]

Screenshot from Grok 3 (in ‘Think' mode).
Claude’s Human-Like Approach: Relatively Slow but Steady
Claude 3.7 Sonnet accurately reported 135 characters in standard mode, counting each character, space, and punctuation mark individually—much like a human might. This method, while precise, lacks the speed of a programming function, highlighting a design choice favouring interpretability over efficiency. Unlike ChatGPT 4o or Perplexity, Claude doesn’t appear to rely on an embedded tool but processes the task organically, aligning with its conversational focus. This human-mimicking approach ensures credibility but sacrifices the rapid execution seen in agent-like systems.
[Read More: Introducing Claude 3.5 Sonnet: A New Challenger in the AI Arms Race!]

Screenshot from Claude 3.7 Sonnet.
DeepSeek’s "DeepThink R1": Thorough but Inefficient
DeepSeek’s 'DeepThink R1' mode took 153 seconds to correct its standard mode’s 150-character overestimate to 135. This mode counted each character—letters, spaces, apostrophes, and punctuation—one by one, splitting the sentence into parts and repeatedly verifying its totals, as seen in its process of identifying a miscount and rechecking the entire sentence. This human-like, iterative approach, marked by multiple self-corrections and statements like “There’s a discrepancy. Where did I go wrong?” and “Let me confirm again”, ensures accuracy but reveals a lack of confidence, driving excessive caution. The 153-second duration—over twice Grok 3’s 73 seconds—underscores inefficiency, prioritizing thoroughness over streamlined execution.

Screenshot from DeepSeek (in standard mode).

Screenshot from DeepSeek (in ‘DeepThink R1’ mode).
Technical Insights: Design Trade-Offs in Play
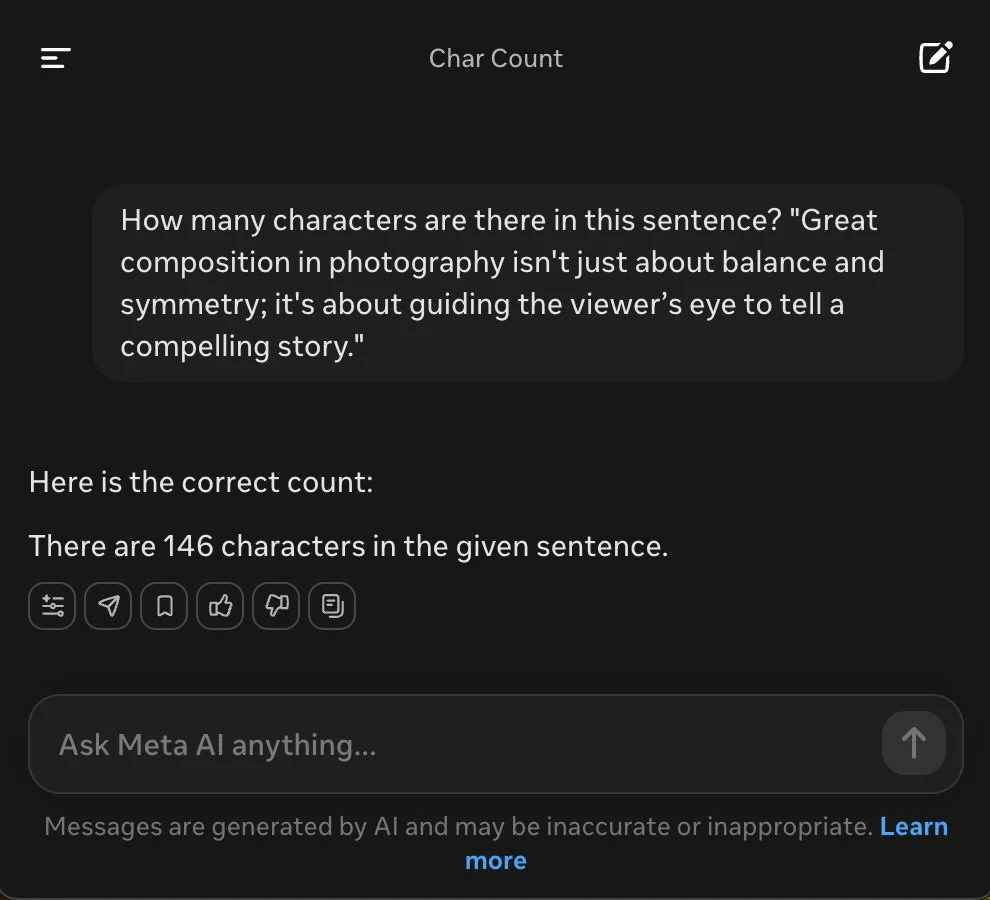
Screenshot from Meta AI.
These results reflect broader design priorities. ChatGPT 4o and Perplexity’s use of programmatic logic showcases how integrating precise tools can overcome the tokenization trap—where models process text as word chunks, missing individual characters—that trips up Grok 3 (standard mode) and DeepSeek (standard mode). Claude’s character-by-character counting avoids tokenization errors but sacrifices speed, while Grok 3’s 'Think' mode and DeepSeek’s 'DeepThink R1' attempt to bridge accuracy and reasoning—Grok with structured steps, possibly via RL, and DeepSeek with repetitive, human-like verification. The inflated counts from POE (139), Meta AI (146) and Gemini 2.0 Flash—153 in Standard mode and 140 in Flash Thinking mode, despite its advanced reasoning claim—suggest hallucination, a common AI issue where models produce incorrect outputs, indicating persistent text-handling flaws even in Gemini’s more sophisticated version.
[Read More: Meta's New AI Venture: Revolutionizing Art Creation with Meta.ai]

Screenshot from Gemini (in standard mode).
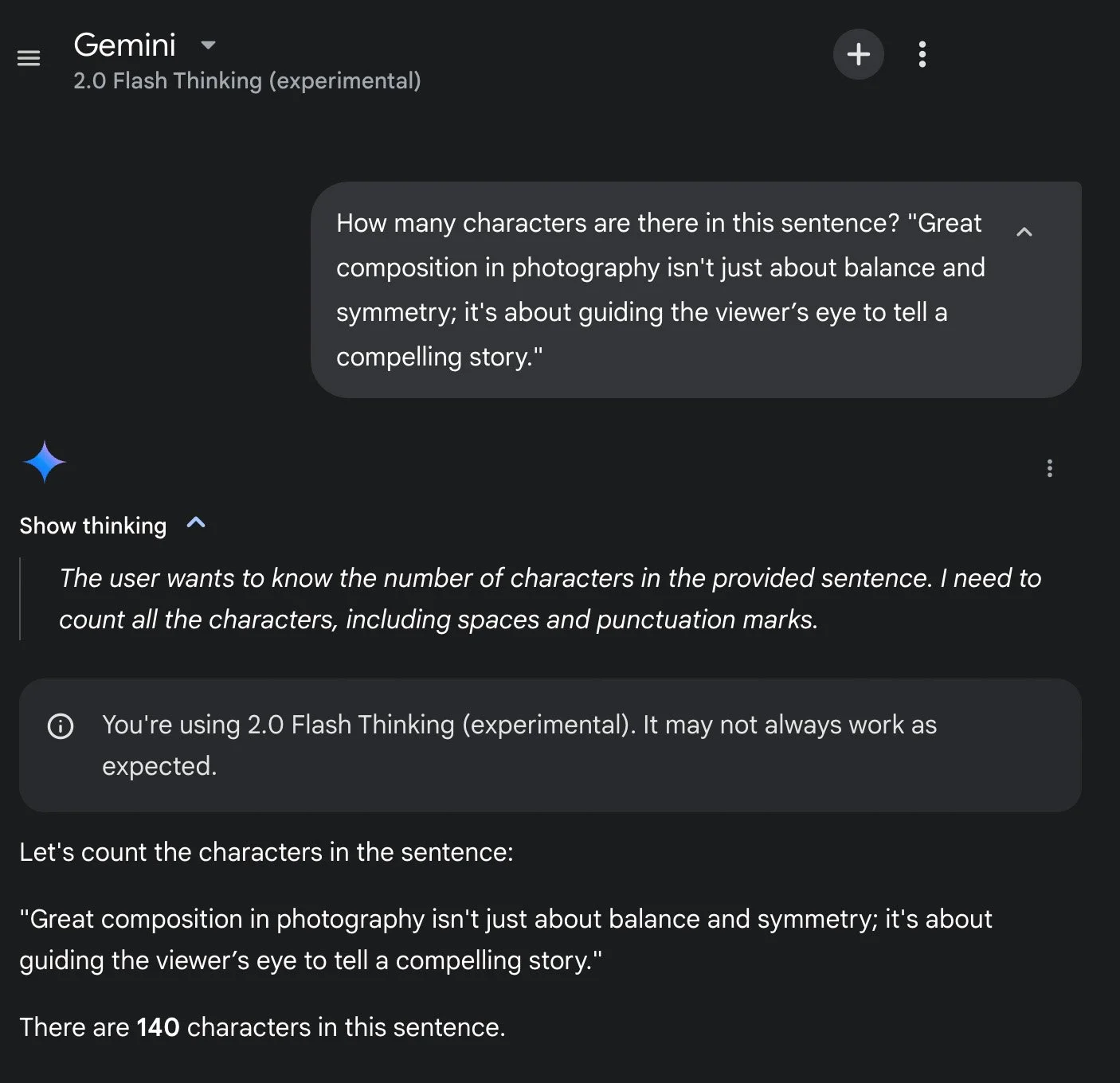
Screenshot from Gemini (in ‘Flash Thinking’ mode).
Implications: Efficiency vs. Accuracy in AI Development
For users, these findings highlight a trade-off: ChatGPT 4o and Perplexity offer fast, reliable results, ideal for practical applications, while Claude provides transparent accuracy at a slower pace. Grok 3 and DeepSeek’s enhanced modes achieve correctness but at a steep time cost, suggesting room for optimization. Developers face a challenge: embedding efficient tools, as seen in ChatGPT 4o, could standardize performance, but the focus on conversational prowess often sidelines such fixes. Currently, no industry-wide solution has emerged, leaving users to choose tools based on their needs—speed, accuracy, or both.
[Read More: Google's Gemini AI Chatbot App Now Available on iPhone]